Warning : update in progress
YASEP is a RISC architecture, so all the instructions have the same fixed structure, while at the same time they try to be generic and orthogonal. This keeps their number low and makes them easy to implement.
YASEP has just one memory addressing mode : contrary to most RISC architectures (load-store architectures), YASEP accesses memory through its registers : it's a register-mapped memory architecture that further reduces the total number of instructions.
In the end, most instructions deal only with registers and immediate data. So all the instructions are formed by a simple 8-bit opcode, followed by two 4-bit register fields ("src1/dest" and "src2"), and an optional 16-bit immediate field (called "Imm16").
Most instructions are available with both 16-bit and 32-bit "forms" (with or without Imm16), they only differ by the value of a single bit, that tells the decoder how to behave.
YASEP32 and YASEP16 only differ in the width of the datapath, while they share the same instruction format and most opcodes.
YASEP's focus is on simplicity and ease of implementation : the instructions are not the most efficient, compact or flexible. There is some room for later improvements but feature creep is currently considered harmful for the project's progress.
The opcode map shows that the opcodes are grouped into 16 groups of 8 (or less) closely related functions. Currently defined groups are :
The YASEP can do things other processors can do. But it's done a bit differently.
First thing to know : the CQ's value. It is inehrent, implicit. It tells you which queue you're running on. Usually, when you start, it is set to 0 so you have (generally) Q1 to Q5 available for other purposes.
Without careful planning and a smart resource allocation, the queues will easily be saturated, leaving no room for further execution. But hey, YASEP is a "small" microcontroller and if there was idle or unused, wasted resources, they would be removed ASAP. So bear with the tight constraints and remember that some people have written webservers on much, much, much more reduced processors.
So the register allocation is usually like this :
| # | Name | Description | Type |
| 0 | A0 | Queue #0's address register, default instruction pointer | Executable queues |
| 1 | D0 | Queue #0's data register, default current instruction | |
| 2 | A1 | Queue #1's address register | |
| 3 | D1 | Queue #1's data register | |
| 4 | A2 | Queue #2's address register | |
| 5 | D2 | Queue #2's data register | |
| 6 | A3 | Queue #3's address register | |
| 7 | D3 | Queue #3's data register | |
| 8 | A4 | Queue #4's address register, stack pointer | Data-only queues |
| 9 | D4 | Queue #4's data register, stack top | |
| 10 | A5 | Queue #5's address register, alternate stack pointer | |
| 11 | D5 | Queue #5's data register, alternate stack top | |
| 12 | R0 | Standard register #0 | Static registers |
| 13 | R1 | Standard register #1 | |
| 14 | R2 | Standard register #2 | |
| 15 | R3 | Standard register #3 |
Having two programmable stacks makes it easy to implement the basic FORTH functions, though it was not the original intention. The first YASEP (VSP) draft included only 4 queues but that was certainly a limitation, so it was increased to 5 queues with the fifth being able to act as a stack.
However static registers are not the most precious resource in a microcontroller, particularly when a queue can emulate one static register (you have to point the address register to a scratch area). Complex or heavy algorithms could even virtually have infinite numbers of registers when playing with the autoincrement features. So lately i decided to put a sixth queue.
Let's start easy. Computational examples here use the static registers so there is no side-effect. Furthermore, the operations use both the short and long instruction forms without raising much issues.
You can familiarize yourself and practice with the interactive Execution Units testbench or interactive assembler, and better understand the issues raised by the operand orders.
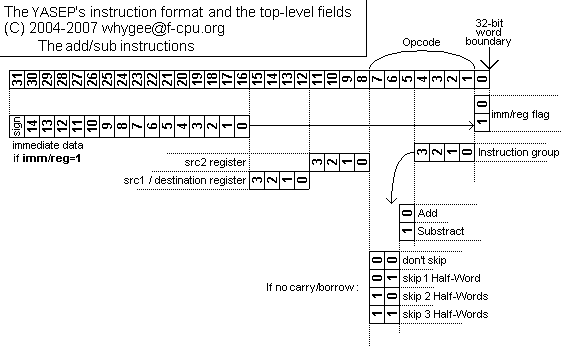
The first execution unit is ASU : it is the "Add and Substract Unit".
add r0 r1; adds r0 and r1, then puts the result in r1 add r0 123 r1; adds r0 and immediate data 123, then puts the result in r1Is that simple enough ?
Now if you want to perform multi-precision computations, the YASEP has no carry flag nor dual-write capability. I used a special instruction to create the carry in a register but it was not very clever in a 2-address processor. So I recently (4/2007) changed this system to a simpler and more powerful one : the instruction skips 0 to 3 half-words
; Addition of R2 to the 64-bit value R0:R1 adds2 r2 r0 ; r0 = r0+r2 ; The next instruction is skipped if no carry was generated add 1 r1 ; carry : r1 = r1+1 (long form : 2 half-words)
The same works for substraction too. The SUB instruction has 3 "skipping" versions that operate the same way. All the available opcodes are summarized below :
ADD ADDition ADDS1 ADD and Skip 1 half-word if carry ADDS2 ADD and Skip 2 half-word if carry SUB SUBstract SUBS1 SUBstract and Skip 1 half-word if carry SUBS2 SUBstract and Skip 2 half-word if carry
This unit is called "ROP2" because it performs all useful Raster OPerations with 2 operands. 16 possibilities exist but several are congruent so 8 boolean operations are available :
| SRC1 | SRC2 | AND | ANDN | NAND | OR | ORN | NOR | XOR | XORN | |
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | |
| 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | |
| 1 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | |
| 1 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
Because of the core's limitations, there is no MUX instruction (unlike F-CPU, it must be emulated with three instructions and a couple of temporary registers).
Note : in the OPN operations (ANDN, and ORN), the source that is inverted is the first one, not the same address as the destination nor the immediate field (when any). This should make it easier to code real stuff. Notice how it impacts the order of the operands :
ANDN r1 r2 ; r2 = r2 & ~r1 ANDN r1 123 r2 ; r2 = 123 & ~r1 ORN r1 r2 ; r2 = r2 | ~r1 ORN r1 123 r2 ; r2 = 123 | ~r1
The "shuffle" unit (SHL) moves bits around the register. It's a very stripped-down version of the corresponding F-CPU unit and it does only rotation and shifts on 32-bit data. These are the 5 basic, unavoidable operations :
SHR logic SHift Right SAR SHift Arithmetic Right SHL logic SHift Left ROL ROtate Left ROR ROtate Right
Note : The ROR and ROL instructions are congruent, but having a single ROT instruction creates an ambiguous problem : should ROT be ROR or ROL of the first 15 positions ? The assembler can emulate ROL with ROR (and vice versa) by negating the immediate operand. However, this is more complex problem with the "shift amount" is given by a register (this impacts the algorithm).
At the binary level, the order of the operands reflects the architectural constraints. In order to keep things useful and practical, the assembler hides these details (remember that the destination/result register is always the last operand). Here comes an example of the syntax :
SHR r1 r2; r2 = r2 >> r1 SHR r1 12 r2; r2 = r1 >> 12 (note that the immediate could be larger but only the 5 LSB are used)
The YASEP contains no load/store unit and treats only 32-bit words. The Insert/Extract unit eases access to 8-bit and 16-bit quantities by shifting words apropriately, with a direct communication with the PFQ's pointers. It is thus possible to have the equivalent of "load" and "store" operations, with the added benefits of pointers that are auto-incremented with the right values. And maybe more in the future.
LSB Load Sign-extended Byte (and inc ptr) LZB Load Zero-extended Byte (and inc ptr) LSH Load Sign-extended 16-bit Half-word (and inc ptr) LZH Load Zero-extended 16-bit Half-word (and inc ptr) SB Store Byte (and inc ptr) SH Store 16-bit Half-word (and inc ptr) SHH Store 16-bit Half-word High (shift it and ignore the pointer) MOV Copy the register or the sign-extended Imm16 field to the destination register.
The shift unit can load bytes from any position. However, because the unit can't cross word boundaries, it can't shift 16-bit words to any position (only offsets 0, 1 and 2 are possible). A trap should be triggered if a pointer offset 3 is found.
The MOV instruction was moved here because the IE instructions are the most similar.
"Load" specifics :
These operations extract one byte or one "word" from a given register. The data is shifted right, according to the implicit pointer associated to this register. If the register is a static register, then the offset is zero. If this is the Data register of a PFQ, the 2 LSBs of the associated pointer are used as offset.
D4 = 12345678h A4 = 00001BADh (offset : A4 & 3 = 1) LSB D4 R1 => R1=56h, A4+=1 now : A4 = 00001BAEh (offset : A4 & 3 = 2) LZB D4 R2 => R2=34h, A4+=1
Note that the long instruction form is not used, because the added immediate is useless. It may be used in the future to extend the offset, using the ASU in parallel to compute a new pointer. But it's too early now.
Note also that the pointer in question is only the 2 LSB of said pointer. When an overflow occurs, the PFQ hardware will increment its own counters to provide the next/previous word from memory. And the pointer's inc/dec flags must also be taken into account...
"Store" specifics :
This is quite similar to the "load" instructions, except that here, the immediate field makes sense in the long instruction form. But then, we have an excess register, or (the other way around) we can't use the extended pointer increment. The chosen approach (today) uses the same form as the load, and either the 2nd operand is used for the stored data (in the short/RR form), or else the immediate field is used (but then the 2nd operand is left unused, so it's not written).
; D4 = 12345678h ; A4 = 00001BADh (offset : A4 & 3 = 1) ; R1 = 9ABCDEF0h SB R1 D4; => D4=1234F078h, A4+=1 ; now : A4 = 00001BAEh (offset : A4 & 3 = 2) SH R1 D4; => D4=DEF0F078h, A4+=2 ; now : A4 = 00001BB0h (offset : A4 & 3 = 0), a new word is loaded in D4=89ABCDEFh SB 0123h D4; => D4=89ABCD23h, A4+=1 ; now : A4 = 00001BB1h (offset : A4 & 3 = 1) SH 4567h D4; => D4=89456723h, A4+=2
The "Store Half-word High" instruction is derived from "Store Half-word", but without checking/using the pointer : it unconditionally shifts the imm/reg's LSB by 16 bits to replace the destination's MSB. The main use is for loading 32-bit immediate data into a register, when preceded by a simple "SH"
SH 5678h R1; => R1=00005678h SHH 1234h R1; => R1=12345678h
Note that SH must come before SHH because SH sign-extends Imm16. The MSB must be corrected by the following SHH :
SH 89ABh R1; => R1=FFFF89ABh (constant is sign-extended) SHH CDEFh R1; => R1=CDEF89ABh
Not all opcodes are used, according to the above descriptions. With some little added HW, it is possible to perform several other operations :
EXPND the 4 LSB of the first operand are "expanded" to 4 byte masks (0 or FFh) and ANDed to the 2nd operand MATCH each byte in src1 is checked for equality with the corresponding byte in src2, creating a bitfield. BMASK each byte in src1 is checked for equality with the corresponding byte in src2, creating a bytemask. BSWAP reverse the word's endian
Because the YASEP is meant to manage byte streams, it must be able to scan through them. A specific operation is provided that detects byte patterns : the MATCH instruction XORs both operands and ANDs the resulting 4 bytes, generating a 4-bit field. This can be used in the detection of byte patterns, the loop running while the result is zero. When it becomes non-zero, the bitfield is useful as an index for computed jumps or calls, to functions that deal with alignment for example.
BMASK is similar but creates a byte mask, instead of a bit field. Like the previous instruction, the immediate field can be used as input for the XOR.
EXPND "expands" the 4 LSBs of the first operand to create a byte mask, too. The result is ANDed to the 2nd operand (register or immediate) to add some flexibility. This is the kind of operation that is useful when doing bitmap graphics, like writing a bitmap font to a byte-map raster, for example
Do i need to explain why BSWAP is useful ? The YASEP is a little-endian machine and might appreciate communication with other "kinds" of computers. Note that the immediate field is useless in this instruction, so it is simply ignored.
Four groups of instructions provide the developper with different granularities of instruction flow control.
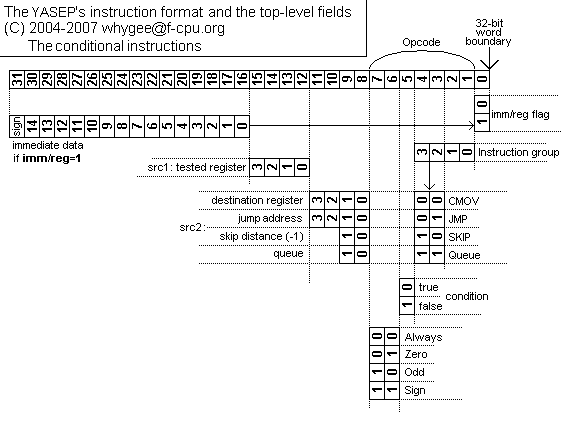
The operands and fields are :
| bit 4 | bit 3 | mode |
| 0 | 0 | CMOV |
| 0 | 1 | JMP |
| 1 | 0 | SKIP |
| 1 | 1 | Q |
| bit 7 | bit 6 | type |
| 0 | 0 | Always |
| 0 | 1 | Zero |
| 1 | 0 | Odd (Not Even) [LSB] |
| 1 | 1 | Sign [MSB] |
| mode | function |
| CMOV | destination register (written) |
| JMP | register containing the target address (read) |
| SKIP | skip length (1 to 16 half-words) |
| Q | target queue (bits 8 and 9 only) |
The different combinations create the 28 following opcodes :
JMP,
JZ,
JNZ,
JO,
JNO,
JS,
JNS,
SKIP,
SZ,
SNZ,
SO,
SNO,
SS,
SNS,
Notes :
Not all the instructions are defined or used currently. Some room is needed for later, and it's not a good idea to fill more than 75% of the opcode space in the first iteration of a CPU architecture.
Here are some intended uses for the remaining opcodes, but the future may prove these forecasts all wrong. Before they are defined, all the opcodes of these groups are marked "TBD" and will behave like INV.
These instructions perform bit test, toggle, set and clear on a word. The location of the words is not clear yet (memory, register, SR or something else).
This group of instructions controls the Simultaneous MultiThreading functions of YASEP. For example, they can create or destroy a thread, read or modify their thread ID, or modify thread properties.
These instructions are optional and TBD later, when YASEP will work correctly in single-thread mode.
These instructions control the prefetch queues, like the auto-update bits of the pointers or the caching strategy.
TBD, it is useless in the current definition of the code (the memory interface is not yet designed).
The last group is clrearly left untouched, except for the INV instruction, which explicitly triggers an invalid opcode exception (for the current and all the future releases). There is no intention to use this group in the not-too-distant future.
More informations (older and written differently) can be found in this text